 I recently found a GnuPG
vulnerability while testing my java-based OpenPGP code. I'll use
this as an excuse to post about testing security code and OpenPGP in
particular, but put it in context with this real-life bug.
I recently found a GnuPG
vulnerability while testing my java-based OpenPGP code. I'll use
this as an excuse to post about testing security code and OpenPGP in
particular, but put it in context with this real-life bug.
A small digression first. Writing security-related software has to be one of the most thankless jobs a programmer can do. You are a nuisance to everyone, but the one time everyone knows what you're doing is when you've made a mistake. At that point you're hung out to dry along your bug for everyone to poke at and feel smug about. So no programmer should cast stones here, for let he who is without sin, etc.
I'm just a satisfied user of gpg, and I'd like to put in a
plug for the GnuPG maintainers. They've been at this thankless job for
a decade and a half, while fixing bugs efficiently and openly. Being
GNU/libre software, what keeps them going is mainly a desire to
contribute to the community. So please say thank you by giving something
back to them if you find gpg useful.
Fuzzing inputs
While you can prove some security results in crypto mathematics, there's no equivalent for crypto programming. The only practical way to know anything about the security of your code is to test it in as many different ways as you can cook up.
A surprisingly productive technique is fuzz testing, where you throw lots of random inputs at every part of your program that reads data.
I'll focus on a specific variation called mutation fuzzing, where you start with a good input and then change parts of it randomly. This idea can be automated easily as it needs little or no knowledge about the data itself. The only thing you need to do is to ensure your code can conveniently accept data from a script.
I was writing some java code that saved and read OpenPGP public keys. So I began by using a good public key, then randomly changed one byte at a time and read it back into the app to see what it did.
I won't trouble you with the many ways I was chastened by this
experiment! But I also used gpg 1.4.11 as a control
application to read the same inputs, and started to see it do some odd
things.
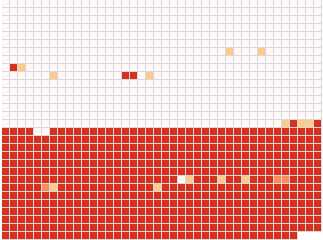
Here is a heat-map of gpg's behavior when fuzzing some public
key. Each little square is a byte in the key, and a byte gets redder
if gpg imports the key even if that byte is modified.
That is, I repeatedly change just the first byte in the key and see if
gpg still imports it. If it never imports the key, I color the first
square nearly white. Otherwise I color it redder, depending on how
often gpg imports it. Then I change just the second byte, and so on.
The first surprise is that you see gpg generally imports the key
even if you change any of the bytes in the second half of the key. You
might think that gpg should never import a key if anything was
changed in it, but the truth is a bit more complex and you'll soon see
why.
You also see a few red squares in the first half, and some not-so-red
squares in the second half. So gpg occasionally accepts keys modified
within the first half too, and it doesn't consistently import every
key from a modified second half either.
To understand what's going on, you have to know a bit about how OpenPGP organizes its data. This is going to get long and detailed, but I promise there is a payoff at the end.
OpenPGP packet structure
OpenPGP is a binary, byte-oriented data format. While you often see PGP ASCII messages, these are just ASCII encodings of the underlying binary data. I'll only talk about the binary format from here on.
This binary format is a concatenated sequence of data
packets. In principle you could simply cat valid PGP
files to form a bigger valid PGP file, though applications may reject
the semantics of such a file.
Each packet is formatted in a classic tag-length-value style. It starts with a tag field that tells you what sort of of a packet it is. This is followed by a length field, saying how many bytes long the following payload is. Then comes the payload for the packet.
 Here is the same key I used before, but now with just its tag and
length fields highlighted in shades of blue. You should see five
packets in it.
Here is the same key I used before, but now with just its tag and
length fields highlighted in shades of blue. You should see five
packets in it.
What are these five packets? It turns out that what we usually call a "PGP public key" is really a list of many public keys, signatures, etc. The specification uses the term OpenPGP certificate rather than "public key" to avoid confusion, and I'll start calling it a certificate too.
 The first and fourth packets are public key packets. If you use
RSA (as this certificate does) you normally use different public keys
for encryption and signing for cryptographic safety. The first public
key -- the so-called master key -- is what actually identifies the
certificate and forms your PGP fingerprint. However, if someone wants
to send you a message, they'll encrypt it with the second public key
found in the certificate.
The first and fourth packets are public key packets. If you use
RSA (as this certificate does) you normally use different public keys
for encryption and signing for cryptographic safety. The first public
key -- the so-called master key -- is what actually identifies the
certificate and forms your PGP fingerprint. However, if someone wants
to send you a message, they'll encrypt it with the second public key
found in the certificate.
Each public key has a small header that describes its type (RSA, etc) followed by a list of integers, which are the actual values used in the public key algorithm. Each integer has a length field followed by a sequence of bytes for the integer.
The integers are the large green sections above, each preceded by a two-byte length in light blue-green. RSA uses two numbers in its public-key method, and you should see two integers in each packet. You may wonder why the first number in each packet is so much longer than the second. The big number is 2048 bits long, and is product of two large primes that only the owner of this key knows. The small number is an exponent used by RSA, and it turns out that the same small prime 65537, is always used in practice.
 The second packet is a user id packet, highlighted here in
yellow. You can see that it's simply a sequence of ASCII (actually,
UTF-8) bytes. This certificate is indeed Linus' PGP certificate, which
he also uses to sign git tags during Linux development.
The second packet is a user id packet, highlighted here in
yellow. You can see that it's simply a sequence of ASCII (actually,
UTF-8) bytes. This certificate is indeed Linus' PGP certificate, which
he also uses to sign git tags during Linux development.
 The third and fifth packets are signature packets, which are
rather complex. An RSA signature ends with a large number, here seen
in green and preceded by its two-byte length in pale blue-green. It is
in the same format as the large numbers found in the public key. This
number is the signature used to verify the data being signed.
The third and fifth packets are signature packets, which are
rather complex. An RSA signature ends with a large number, here seen
in green and preceded by its two-byte length in pale blue-green. It is
in the same format as the large numbers found in the public key. This
number is the signature used to verify the data being signed.
You will see a two-byte white area in each packet. OpenPGP originally used it to hold a "quick-check" hash of the data to let implementations quickly reject bad files without needing to run the more expensive cryptographic signature check. However, someone discovered a chosen-plaintext attack if implementations actually used these bytes as intended. So in practice, these two bytes are just ignored.
An OpenPGP signature has an additional purpose, it adds metadata to the thing it is signing. For instance, it includes the type of signature, the time it was signed, and other metadata specific to a given type of signature.
Surprisingly, this metadata itself doesn't have to be completely signed, and a signature typically contains both signed and unsigned metadata. The signed metadata in this key is in dark purple, followed by the unsigned metadata in light purple. If you look carefully, you'll also see that each metadata sequence is preceded by a two-byte length header in a different shade of purple.
The first signature packet is a self-signature, indicating that it applies to the preceding master public key and the user ID packet. The signature is created using the master key itself. It's really just a way to prove that nobody has changed the public key, connect the user id with that key, and add metadata about the key like the preferred cryptographic algorithms to use when communicating with the owner, etc.
The second signature packet is a sub-key signature, indicating that it is a signature on the second public key packet. This signature is also created using the master key, and the metadata on this signature tells you to use this second public key for encryption. If you trust the first public key, verifying this signature lets you trust the second public key as well.
Structure + heatmap = insight
If you're still with me, here's the payoff. We can overlay the heatmap on top of the data structures in the certificate, and look for correlations.

(Mouseover the image to show the heatmap on top of the packets.)
You can immediately see what's going on with the second half of the
key. gpg generally imports the key if we're fuzzing bytes starting
with the second public key. In fact, what gpg actually does is to
only import the master key, but not the encryption key. This doesn't
cause problems, and is arguably a best-effort by gpg to use what
keys it can extract from the certificate.
What's a bit more interesting is that it doesn't consistently import
the first key in this situation. It appears that fuzzing certain bytes
in the second key can cause it to reject the first key as well. For
example, changing the length field of the big number in the second
public key causes it to reject the entire certificate. One thing you
can conclude is that gpg probably uses a two-pass approach to
import keys, as keys are not imported as soon as they are verified.
If you look carefully you'll soon notice that most of the problems are around the length fields of a packet or the length field of a data structure within a packet. This is a common issue with most code that parses binary data.
For example, take the very first pale red spot in the first public-key packet. You'll notice it occurs within the length field of the small second number of the master key.
The length field here counts the number of bits to use from the
following bytes, and the spec also demands that it never contain
leading zeros. The length field on the second number is 17 bits, but
if you change it to (say) 18 bits, gpg fails to flag it as an
error because the parser fails to check for leading zeros as the spec
requires. But it still remains the same number, and doesn't cause
obvious problems. So, a minor bug in gpg.
More importantly, why doesn't the signature verification fail even though we've altered bytes in the public key packet? It turns out that self-signatures don't sign raw bytes in the public key. What they actually sign is a canonical representation of these numbers after they have been parsed. So, a subtle bug in data parsing like this is not detectable by OpenPGP self-signatures.
You will find a similar situation with the red blob on top of the user id tag byte. It turns out that there are two different, but correct ways to represent a user id tag. This packet too is transformed into a canonical form before parsing, and hence not detectable by the signature.
Another interesting area is the length field on the signature
packets. Look for two fairly red bytes right after the user packet and
on the length field of the signature packet. Why does gpg mostly
accept the key even if these bytes are changed?
Each data structure within a signature is either a fixed size, or has
a length, and gpg uses this information to parse the signature
packet and generally ignores the overall signature length. As you
might guess -- the signature packet length is not part of the
signature, so it is not detected during verification.
You can also fuzz parts of the unsigned meta-data as well, which is to be expected.
Ok. None of these look like major problems, so where is the
vulnerability in gpg anyway? It was a combination of its
two-pass approach to add keys, together with with incorrectly cleaning
up data structures after it failed to parse a fuzzed packet. This
happened when fuzzing the bytes that start the second public
key. Normally, it is unable to parse the rest of the data as you might
expect; but every so often it would misidentify it as a completely
different packet, run into errors parsing that packet, and then fail
to clean up the partially created data structures.
This wouldn't have caused a real problem, except that when gpg
went back to add the first key, it traversed some of these bad data
structures and landed into memory-access trouble. The fix was to
skip parsing packets
in public key certificates if it hit one of the bad packet types.
By now, you might be wondering about other types of fuzzing attacks. For instance, could you reorder OpenPGP packets and see what happens, and so on. These are of course good ways to continue testing, and starts to enter a technique called "generative" fuzzing. This uses a deeper knowledge of the data, and typically tries to generate (rather than mutate) funny inputs.
Generative fuzzing is very useful, though it usually takes more effort because you need to understand the format of the data to be effective. I've focused on mutative fuzzing because it's pretty useful just by itself, and takes very little effort to do.
Conclusions
What did I learn from all this, including the bugs I found in my own app?
In the math behind cryptography, you can prove certain bounds that help you understand its "goodness". But in practical cryptographic code, there's isn't a way to know how secure it really is without testing it. So testing is a necessary (though not sufficient) way to understand the security of the system.
A surprisingly effective test is to blindly and randomly bash at all the inputs to your application. In fact, variations of this method are widely used in hardware design and I've been been guilty of not paying enough attention to it.
Also, complex data formats and protocols greatly increase the chances of security bugs in any implementation, and it's not a linear increase with complexity.
Code to handle increasing complexity quickly hits a threshold where you cannot simply intellectually analyze it for security holes. It also gets worse if parts of the code are implemented by different people.
So if you're designing a new security-related format or protocol, it's just as important to keep it simple to make the implementations more secure.